K8s resource Limits; When "all you can eat" becomes "sir, we're going to need that plate back"
K8s is often misunderstood on how it manages resources on a node. A widespread misconception is that a pod without CPU or memory limits will consume all available resources on its node. That’s not how it works.
TL;DR I strongly reccomend setting limits == requests, unless you have a very specific reason not to (i.e. your nodes are on Linux kernel <6.6 and still using CFS).
How K8s manages resources
There are two relevant resource parameters that will be important for us that we can define at container level:
- Requests: The minimum amount of resources guaranteed to the container. This is like reserving a table at a restaurant and nobody else can take it, even if you’re running late or not showing up at all.
- Limits: The maximum amount of resources the container is allowed to use. This is like reserving a table with a specific time and being kicked out after the reserved time.
To better understand this, let’s imagine a node with 4 CPUs hosting two pods:
Scenario 1: Reserved Resources
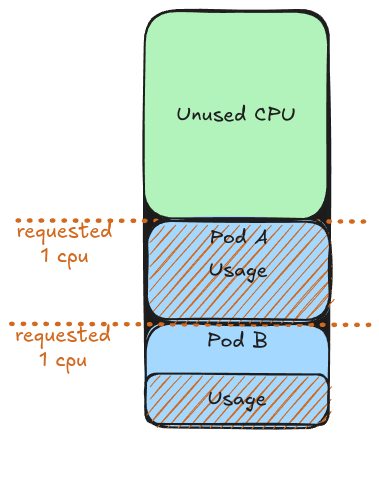 When we set:
When we set:
- requests.cpu = 1
- limits.cpu = 1
Each pod gets exactly the amount of CPU it requested. Even if the pod doesn’t use all of its reserved CPU, no other pod can use the available leftover.
Scenario 2: Burstable Resources
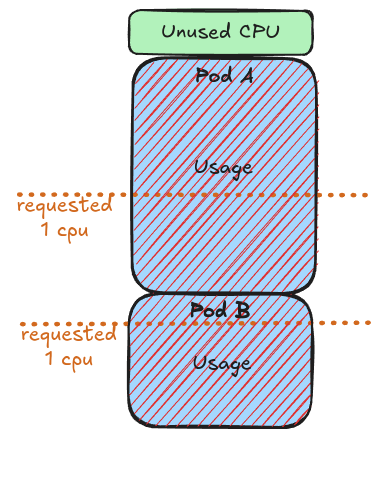 When we set:
When we set:
- requests.cpu = 1
- No CPU limit
Here we go, this is now wild west; Since no CPU limits are set, pods can burst beyond their requested amount and use any available CPU on the node. This creates a shared pool of resources it may improves resource utilization efficiency and pod density potentially saving you some bucks, however variable access to resources leads to a significant trade-off: workloads with unpredictable and inconsistent performance.
The downside of variable resource access on system performance
-
end users start question their mental health
K8s clusters should deliver consistent performance for applications, independent of what else is running on the host. Burstable pods, can create an inconsistent user experience, the same app may respond blazingly fast one minute and mysteriously fail the next for exactly identical requests. Users may start clearing caches, switching browsers, or restarting their devices, convinced that the issue is on their end, especially when it seems to work fine on a peer’s device not knowing that the real issue is your K8s with a deployment where requests are not set equals limits.
-
Developers start question their mental health
Developers quickly become accustomed to non-guaranteed resources. It’s like getting used to an all-you-can-eat restaurant and then suddenly switching to rationed portions. Their pod mysteriously slow down and they may think “Was it a bad commit? Where is my CPU?” well…those resources were never yours to begin, Another point is wow can we possibly load test the app or create nice developers that perform similar to prod?.Finally I may ask,would developers rather build for Apple closed garden with predictable hardware or the wild west of Android/Windows with their infinite hardware variations?
Conclusion
So unless you enjoy late night Slack messages or Pagerduty notifications asking why the production environment is suddenly slow or crashing, set that CPU/Memory limits == requests, your end-users, developers, and your blood pressure will all be better for it knowing your containers won’t be battling each other over resources.
Note on CFS and EEVDF
Old Linux CPU scheduler(CFS) enforces CPU limits using burst quotas, which may throttle pods that exceed their limits, even when the node CPU isn’t fully utilized. This may cause latency spikes and inconsistent performance. So, before setting requests == limits be sure your nodes are running Linux kernel 6.6 or newer, where they introduced EEVDF CPU scheduler.